이전 글에서는 Kafka와 RabbitMQ의 이론에 대해서 알아보았다.
이번에는 프로젝트에서 사용한 Spring boot + Python을 Kafka와 연결하여 사용하는 방법에 대해서 설명하고자 한다.
해당 포스트는 이론적인 부분은 모두 제외되었기 때문에, 이론부터 공부를 하고자 한다면 이전 글을 참고하길 바랍니다.
Kafka와 RabbitMQ를 알아보자
이번에 알아볼 Kafka와 RabbitMQ는 두 어플리케이션, 프로세스 등 간의 메세지를 교환할 때 사용하는 플랫폼입니다.첫 번 째 게시글은 Kafka와 RabbitMQ에 대해 이론적으로 알아보고, 다음 게시글은 Sprin
seungyong20.tistory.com
해당 관련 코드들은 모두 Github에서 확인하실 수 있습니다.
blog/kafka at main · seungyong/blog
Tistory 블로그를 위한 예제 소스 코드 작성입니다. Contribute to seungyong/blog development by creating an account on GitHub.
github.com
Docker
Docker Desktop 설치
Windows
Get started with Docker for Windows. This guide covers system requirements, where to download, and instructions on how to install and update.
docs.docker.com
Docker + GUI 환경을 제공하는 Docker Desktop을 설치한다. 이 부분에서는 각 운영체제에 맞춰 설치하면 되기 때문에 따로 설명을 하지 않겠습니다.
Kafka + Kafka-ui 설치
Kafka와 Kafka의 상태를 모니터링하기 위한 Kafka-ui를 Docker를 통해 설치하겠습니다.
docker-compose.yml
전체 코드 보기
networks:
kafka_network:
driver: bridge
volumes:
kafka01:
driver: local
kafka02:
driver: local
kafka03:
driver: local
services:
kafka01:
image: bitnami/kafka:latest
container_name: kafka01
networks:
- kafka_network
volumes:
- kafka01:/bitnami/kafka
ports:
- 10000:9094
environment:
- KAFKA_CFG_BROKER_ID=1
- KAFKA_CFG_NODE_ID=1
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_KRAFT_CLUSTER_ID=HsDBs9l6UUmQq7Y5E6bNlw
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka01:9093,2@kafka02:9093,3@kafka03:9093
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka01:9092,EXTERNAL://127.0.0.1:10000
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
kafka02:
image: bitnami/kafka:latest
container_name: kafka02
networks:
- kafka_network
volumes:
- kafka02:/bitnami/kafka
ports:
- 10001:9094
environment:
- KAFKA_CFG_BROKER_ID=2
- KAFKA_CFG_NODE_ID=2
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_KRAFT_CLUSTER_ID=HsDBs9l6UUmQq7Y5E6bNlw
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka01:9093,2@kafka02:9093,3@kafka03:9093
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka02:9092,EXTERNAL://127.0.0.1:10001
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
kafka03:
image: bitnami/kafka:latest
container_name: kafka03
networks:
- kafka_network
volumes:
- kafka03:/bitnami/kafka
ports:
- 10002:9094
environment:
- KAFKA_CFG_BROKER_ID=3
- KAFKA_CFG_NODE_ID=3
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_KRAFT_CLUSTER_ID=HsDBs9l6UUmQq7Y5E6bNlw
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka01:9093,2@kafka02:9093,3@kafka03:9093
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka03:9092,EXTERNAL://127.0.0.1:10002
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
networks:
- kafka_network
depends_on:
- kafka01
- kafka02
- kafka03
ports:
- 8090:8080
environment:
- DYNAMIC_CONFIG_ENABLED=true
- KAFKA_CLUSTERS_0_NAME=kafka-clusters
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka01:9092,kafka02:9092,kafka03:9092환경 변수에 대한 설명
| 컨테이너 | 설정 이름 | 설명 |
| kafka | KAFKA_CFG_BROKER_ID | Kafka 인스턴스 ID 반드시, 고유한 ID를 가져야한다. |
| KAFKA_CFG_NODE_ID | Kafka에서 KRaft를 사용하기 위해서는 NODE_ID를 반드시 지정해야 한다. | |
| KAFKA_ENABLE_KRAFT | Kraft 사용 여부 | |
| KAFKA__KRAFT_CLUSTER_ID | Cluster의 고유한 ID | |
| ALLOW_PLAINTEXT_LISTENER | PLAINTEXT를 사용한 통신 여부 암호화가 되지 않은 통신 |
|
| KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE | 토픽 자동 생성 여부 | |
| KAFKA_CFG_CONTROLLER_QUORUM_VOTERS | 메타데이터, 각종 정보를 저장 관리 하기 위한 Controller 선출 목록 | |
| KAFKA_CFG_LISTENERS | 내부, 외부 통신 주소 + 포트 설정 | |
| KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP | 통신할 때 사용할 프로토콜을 지정 현재, 모든 값은 암호화 되지 않은 형식으로 진행 (PLAINTEXT) |
|
| KAFKA_CFG_PROCESS_ROLES | 해당 Kafka 서버가 무슨 역할을 할지 정하는 설정 KRaft를 사용하기 위해 반드시 필요하다. controller : 메타데이터 관리, 리더와 팔로우 선출 관리 등 broker : 일반 데이터 관리로써, 메시지를 주고 받고 파티션에 저장하는 역할 |
|
| KAFKA_CFG_CONTROLLER_LISTENER_NAMES | 다른 브로커나 컨트롤러와 통신할 때 사용할 리스너 이름 KRaft를 사용하기 위해 반드시 필요하다. |
|
| kafka-ui | KAFKA_CLUSTERS_0_NAME | 표시할 클러스터 이름 |
| KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS | 클러스터에 등록된 Kafka 서버의 목록 | |
| DYNAMIC_CONFIG_ENABLED | 브로커의 설정이 바뀌면 Kafka 클러스터의 브로커 재시작 없이 동적으로 설정을 바꿔주는 역할 |
docker-compose.yml 실행
cmd를 열고 docker-compose.yml이 있는 곳까지 이동하고, 다음과 같은 명령어를 작성한다.
docker-compose -f docker-compose.yml up -d
이러한 창이 뜨면 성공한겁니다.

http://localhost:8090/ui/clusters/local/brokers를 입력 후 들어가면 Broker1이 리더 브로커로 승격되어 있는 모습을 볼 수 있다.
Code
코드를 최대한 단순화 시키기 위해 다음과 같은 로직을 만들겠습니다.
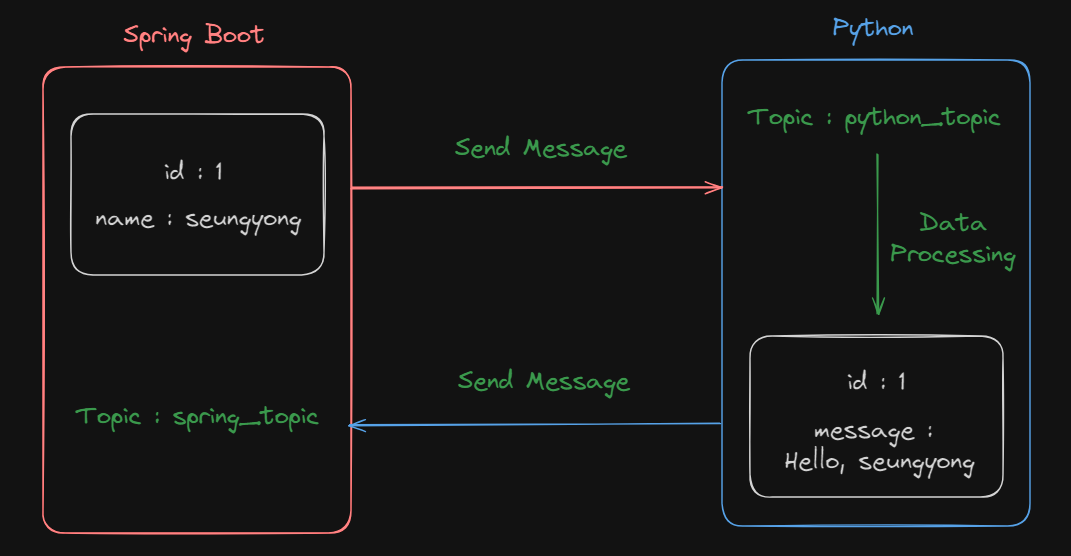
Spring boot
build.gradle
dependencies {
// ... 이전 코드
implementation 'org.springframework.kafka:spring-kafka',
}
RequestKafkaDto
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class RequestKafkaDto {
private Long id;
private String name;
}
ResponseKafkaDto
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class ResponseKafkaDto {
private Long id;
private String message;
}
application.properties
spring.application.name=kafka-spring
# Kafka
spring.kafka.bootstrap-servers=localhost:10000,localhost:10001,localhost:10002
spring.kafka.consumer.group-id=test-group
spring.kafka.consumer.auto-offset-reset=latest
spring.kafka.consumer.enable-auto-commit=false| 키 | 설명 |
| bootstrap-servers | Kafka 서버의 주소 목록 |
| consumer.group-id | Consumer의 기본 그룹 ID |
| consumer.auto-offset-reset | Kafka 서버 구동 시 Consumer의 메시지를 어디서부터 읽을지 설정하는 변수 earliest : 앞에서부터 읽는다. latest : 뒤에서부터 읽는다. |
KafkaProducerConfig
package seungyong20.tistory.kafkaspring.config;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.kafka.support.serializer.JsonSerializer;
import seungyong20.tistory.kafkaspring.dto.RequestKafkaDto;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
@Slf4j
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
/**
* 메시지를 보내기 위한 ProducerFactory를 생성합니다.
* Key는 String, Value는 RequestKafkaDto로 설정합니다.
*/
@Bean
public ProducerFactory<String, RequestKafkaDto> producerFactory() {
log.info("Creating producer factory");
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
/**
* KafkaTemplate을 생성합니다.
* Key는 String, Value는 RequestKafkaDto로 설정합니다.
*/
@Bean
public KafkaTemplate<String, RequestKafkaDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
KafkaConsumerConfig
package seungyong20.tistory.kafkaspring.config;
import com.fasterxml.jackson.core.JsonParseException;
import seungyong20.tistory.kafkaspring.dto.ResponseKafkaDto;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.errors.SerializationException;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ContainerProperties;
import org.springframework.kafka.listener.DefaultErrorHandler;
import org.springframework.kafka.support.serializer.ErrorHandlingDeserializer;
import org.springframework.kafka.support.serializer.JsonDeserializer;
import org.springframework.util.backoff.BackOff;
import org.springframework.util.backoff.FixedBackOff;
import java.net.SocketTimeoutException;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
@Configuration
@EnableKafka
@Slf4j
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.consumer.group-id}")
private String groupId;
@Value("${spring.kafka.consumer.auto-offset-reset}")
private String autoOffsetReset;
@Value("${spring.kafka.consumer.enable-auto-commit}")
private String enableAutoCommit;
private final Long interval = 1000L;
private final Long maxAttempts = 3L;
@Bean
public ConsumerFactory<String, ResponseKafkaDto> consumerFactory() {
log.info("Creating consumer factory");
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 각 Consumer 인스턴스를 식별하기 위한 고유한 ID를 생성합니다.
configProps.put(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, UUID.randomUUID().toString());
configProps.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
configProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
configProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
// JSON 데이터를 ResponseKafkaDto로 역직렬화하기 위한 JsonDeserializer를 생성합니다.
JsonDeserializer<ResponseKafkaDto> deserializer = new JsonDeserializer<>(ResponseKafkaDto.class);
// ErrorHandlingDeserializer를 사용하여 예외가 발생했을 때 처리를 수행합니다.
ErrorHandlingDeserializer<ResponseKafkaDto> errorHandlingDeserializer = new ErrorHandlingDeserializer<>(deserializer);
// Kafka ConsumerFactory를 생성합니다. Key는 String, Value는 ResponseKafkaDto로 설정하고, 에러 발생 시 처리를 위해 ErrorHandlingDeserializer를 사용합니다.
return new DefaultKafkaConsumerFactory<>(configProps, new StringDeserializer(), errorHandlingDeserializer);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, ResponseKafkaDto> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, ResponseKafkaDto> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(1);
factory.setCommonErrorHandler(errorHandler());
return factory;
}
@Bean
public DefaultErrorHandler errorHandler() {
BackOff fixedBackOff = new FixedBackOff(interval, maxAttempts);
DefaultErrorHandler errorHandler = new DefaultErrorHandler((consumerRecord, e) -> {
log.error("Error occurred while processing: {} and value : {}", e, consumerRecord.value());
}, fixedBackOff);
errorHandler.addRetryableExceptions(SocketTimeoutException.class);
errorHandler.addNotRetryableExceptions(NullPointerException.class);
errorHandler.addNotRetryableExceptions(JsonParseException.class);
errorHandler.addNotRetryableExceptions(SerializationException.class);
return errorHandler;
}
}
설명이 필요한 코드들은 하나하나씩 알아보겠습니다.
configProps.put(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, UUID.randomUUID().toString());각 Consumer 인스턴스를 식별하기 위해 고유한 UUID를 생성합니다.
JsonDeserializer<ResponseKafkaDto> deserializer = new JsonDeserializer<>(ResponseKafkaDto.class);
ErrorHandlingDeserializer<ResponseKafkaDto> errorHandlingDeserializer = new ErrorHandlingDeserializer<>(deserializer);ResponseKafkaDto를 Json 형태로 바꾸고, 역직렬화 단계에서 에러가 발생할 시 오류를 핸들링하기 위해 ErrorHandlingDeserializer로 래핑합니다.
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);MANUAL_IMMEDIATE는 Acknowledgement.acknowledge() 메소드를 호출하면 즉시, 메시지를 정상적으로 처리했다라는 것을 알리게 합니다.
factory.setConcurrency(1);Consumer가 동시에 몇 개로 운영될지를 정합니다. 즉, 1로 설정하였다면 Consumer는 1개의 스레드로 메시지를 처리합니다.
BackOff fixedBackOff = new FixedBackOff(interval, maxAttempts);
DefaultErrorHandler errorHandler = new DefaultErrorHandler((consumerRecord, e) -> {
log.error("Error occurred while processing: {} and value : {}", e, consumerRecord.value());
}, fixedBackOff);interval 초마다 최대 maxAttempts만큼 재시도를 합니다.
log 부분에서 실패 토픽에 메시지를 보내기, 또 다른 처리를 할 수 있지만, 지금은 log만 남기도록 하겠습니다.
errorHandler.addRetryableExceptions(SocketTimeoutException.class);
errorHandler.addNotRetryableExceptions(NullPointerException.class);
errorHandler.addNotRetryableExceptions(JsonParseException.class);
errorHandler.addNotRetryableExceptions(SerializationException.class);SocketTimeoutException은 일시적인 네트워크 문제일 수 있기 때문에 재시도를 하고, NullPointer, JsonParse, Serialization은 단순 데이터 문제이기 때문에 즉시 오류를 발생시킵니다.
KafkaProducer
@Slf4j
@Component
@RequiredArgsConstructor
public class KafkaProducer {
private final KafkaTemplate<String, RequestKafkaDto> kafkaTemplate;
public void sendMessage(String topic, String key, RequestKafkaDto requestKafkaDto) {
log.info("Producing {} message: {}", key, requestKafkaDto);
kafkaTemplate.send(topic, key, requestKafkaDto);
}
}
KafkaConsumer
@Slf4j
@Getter
@Setter
@Component
public class KafkaConsumer {
// spring_topic을 가입하여, 메시지를 기다림
@KafkaListener(topics = "spring_topic")
public void listen(ConsumerRecord<String, ResponseKafkaDto> record, Acknowledgment acknowledgment) {
try {
// 전달 받은 값의 key 가져오기
String key = record.key();
// 전달 받은 값의 value 가져오기
ResponseKafkaDto payload = record.value();
log.info("Received message: key={}, id={}, message={}", key, payload.getId(), payload.getMessage());
} catch (Exception e) {
log.error("Error occurred while consuming message: {}", e.getMessage());
} finally {
// 메시지 처리가 되었음 알림
acknowledgment.acknowledge();
}
}
}
KafkaController
원래는 Service, Repository 등을 통해 데이터를 검증 및 가공하여 보내지만, 여기에서는 단순하게 메시지 전송만 하겠습니다.
@RequiredArgsConstructor
@RestController
@RequestMapping("/kafka")
public class KafkaController {
private final KafkaProducer kafkaProducer;
@PostMapping
public ResponseEntity<?> sendMessage() {
kafkaProducer.sendMessage("python_topic", "test_key", new RequestKafkaDto(1L, "seungyong"));
return ResponseEntity.noContent().build();
}
}
Python
python 관련 코드들은 코드들이 상당히 직관적이기 때문에 설명이 따로 필요하지 않을 거 같아서 생략하겠습니다.
kafka 라이브러리 설치
pip install kafka-python
# .env를 가져오기 위한 라이브러리
pip install python-dotenv
.env
bootstrap-servers=localhost:10000,localhost:10001,localhost:10002
group-id=test-group
consumer-topic=python_topic
producer-topic=spring_topic
log.py
Log 관련은 자세히 다루지 않겠습니다.
import logging
import os
class Logger:
def __init__(self, name):
self.directory = os.getcwd() + "/log/"
if not os.path.exists(self.directory):
os.makedirs(self.directory)
self.logger = logging.getLogger(name)
if not self.logger.hasHandlers():
self.logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# Stream handler
stream_handler = logging.StreamHandler()
stream_handler.setFormatter(formatter)
self.logger.addHandler(stream_handler)
# File handler
file_handler = logging.FileHandler(f'{self.directory}/{name}.log')
file_handler.setFormatter(formatter)
self.logger.addHandler(file_handler)
consumer.py
import json
import os
from kafka import KafkaConsumer
from log import Logger
from producer import Producer
from dotenv import load_dotenv
load_dotenv()
consumer_topic = os.environ.get("consumer-topic")
group_id = os.environ.get("group-id")
bootstrap_servers = os.environ.get("bootstrap-servers").split(",")
class Consumer:
broker = ""
topic = ""
group_id = ""
logger = None
consumer = None
producer = None
def __init__(self):
self.logger = Logger(name='consumer').logger
self.broker = bootstrap_servers
self.topic = consumer_topic
self.group_id = group_id
self.consumer = KafkaConsumer(
bootstrap_servers=self.broker,
group_id=self.group_id,
auto_offset_reset='latest',
enable_auto_commit=True,
value_deserializer=lambda m: json.loads(m.decode('utf-8')),
)
self.producer = Producer()
self.consumer.subscribe([self.topic])
def run(self):
self.logger.info('Starting Consumer...')
for message in self.consumer:
self.logger.info('Receive Message')
key = str(message.key, 'utf-8') if message.key else 'default_key'
is_json = isinstance(message.value, dict)
if not is_json:
self.logger.error('Not Json type')
continue
self.logger.info(f"Receving {key} message id : {message.value['id']} value : {message.value['name']}")
self.producer.send_message('python_key', {
'id': message.value['id'],
'message': f"Hello, {message.value['name']}"
})
producer.py
import json
import os
from dotenv import load_dotenv
from kafka import KafkaProducer
from log import Logger
load_dotenv()
producer_topic = os.environ.get("producer-topic")
bootstrap_servers = os.environ.get("bootstrap-servers")
class Producer:
broker = ""
topic = ""
producer = None
logger = None
def __init__(self):
self.logger = Logger(name='producer').logger
self.broker = bootstrap_servers
self.topic = producer_topic
self.producer = KafkaProducer(
bootstrap_servers=self.broker,
key_serializer=lambda x: bytes(x, encoding='utf-8'),
value_serializer=lambda x: json.dumps(x).encode('utf-8'),
retries=3
)
def send_message(self, key, message):
try:
self.producer.send(
topic=self.topic,
key=key,
value=message
)
self.producer.flush()
except Exception as e:
self.logger.error(f"Error sending message to {self.topic}: {message} cause {e.__str__()}")
사용
이제 실제로 구동해서 서로 데이터를 주고받는지 확인을 해보자.
구동
Spring boot
consumer의 spring_topic 가입과 동시에, consumer가 등록되었다는 로그가 뜨면 성공한겁니다.

Python
단순하게, Starting Consumer...라는 로그가 찍히면 성공한겁니다.

실행
Spring boot
Producer가 메시지를 보냈다는 문구가 뜨면 됩니다.

또한, Python 측에서 데이터를 가공 후 보낸 값도 잘 받아졌는지 봐야합니다.

Python
Python 측 또한 내가 보낸 값들이 받아졌습니다.

만약, Spring에서 10000개의 메시지가 발행된다면?
스레드 1개
자바도 스레드 1개, python도 스레드 1개로 처리해서 순차적으로 처리되는 것을 볼 수 있습니다.
스레드 5개
Spring은 다음과 같이 바꿨습니다.
// KafkaConsumerConfig.java
factory.setConcurrency(5);
Python은 다음과 같이 바꿨습니다.
import concurrent.futures
# ...
class Consumer:
# ...
def __init__(self):
# ...
self.executor = concurrent.futures.ThreadPoolExecutor(max_workers=5)
def run(self):
self.logger.info('Starting Consumer...')
try:
for message in self.consumer:
self.executor.submit(self.process_message, message)
except Exception as e:
self.logger.error(f'Failed process message : {e}')
finally:
self.executor.shutdown(wait=True)
def process_message(self, message):
self.logger.info('Receive Message')
key = str(message.key, 'utf-8') if message.key else 'default_key'
is_json = isinstance(message.value, dict)
if not is_json:
self.logger.error('Not Json type')
return
self.logger.info(f"Receving {key} message id : {message.value['id']} value : {message.value['name']}")
self.producer.send_message('python_key', {
'id': message.value['id'],
'message': f"Hello, {message.value['name']}"
})
마무리
졸업 작품 하면서 Spring boot와 Python 서버 간의 비동기 작업 및 통신할 수 있는 솔루션이 필요했고, 최근에 많이 사용한다는 Kafka를 사용해보았습니다. 물론 오버 엔지니어링이라 효율은 떨어지지만 새로운 기술을 사용해보고자라는 마음이 컸습니다.
또한, Kafka를 클러스터링 해 여러 대를 두지 않았지만, 포스팅할 때만큼은 여러 대로 두고, 스레드도 5개로 늘려 처리해보았습니다. 컴터가 안 좋아서 렉이 걸리네요...
References
'Project 하면서 알아가는 것들' 카테고리의 다른 글
| JPA의 N + 1 문제를 알아보고 해결하자 (0) | 2025.03.23 |
|---|---|
| @Transactional의 readonly와 OSIV는 뭐 하는 친구일까? (0) | 2025.03.19 |
| Kafka와 RabbitMQ를 알아보자 (0) | 2024.08.20 |
| [Nextjs] Tiptap 사용법과 커스텀마이징 기능 구현 (1) | 2024.02.28 |
| IoC, DI, DPI 확실히 개념 잡기 (0) | 2023.11.12 |